Random Forest (RF)
Train each tree independently, using a random sample of the data.
Pros:
-
Reduced risk of overfitting
-
Provides flexibility
-
Easy to determine feature importance Cons:
-
Time-consuming process
-
Requires more resources
-
More complex https://www.ibm.com/cloud/learn/random-forest
-
RF uses random feature selection, which lowers correlation and therefore the variance of the regression trees
-
How to build a Random Forest?
- Bootstraped new Datasets for RF
- create new dataset from original one with same nr of entries
- entries are picked randomly
- Random Sampling with Replacement → choose entries for new DS randomly
- Randomly Select features for each new DS and train new DT
- A new data point gets passed through each DT and note the predictions
- All predictions are combined, and through majority voting the prediction is made
- The process of combining results from multiple models is called Aggregation.
-
Bagging = Bootstrapping + Aggregation
- Bootstrapping with not the entirety of the features makes our RF less sensitive to training data
-
What is the ideal size of the feature subset used for training our DTs?
- Research shows that a nr close to the log or sqrt of the total number of features is good https://www.youtube.com/watch?v=v6VJ2RO66Ag
Taken from https://corporatefinanceinstitute.com/resources/data-science/random-forest/
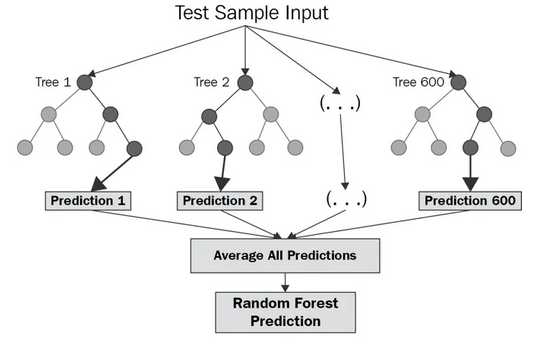
Q: What is the difference between Classification and Regression?
- Both are supervised machine learning
- Classification works with a categorical response variable
- Regression works with a continuous response variable
Q: What model to use for a rating prediction (1-5 Stars)?
- Ratings are ordinal numbers and maintain a natural ordering. Therefore we can use a regression Model.
- If we discard the ordering, we can also use a classification model.
- Source: 1 to 5 Star Ratings — Classification or Regression? | by Sebastian Poliak | Towards Data Science
- This paper suggests that Maximum Entropy Classification models performs better than regression models for rating systems
Maximum Entropy Text classification means: start with least informative weights (priors) and optimize to find weights that maximize the likelihood of the data, the P(D). Essentially, it’s the EM algorithm.
Q: How can RF be used for a regression model? A: When combining the predictions of our DTs (aggregation), we can take the mean over all predictions for get a continuous number. We are basically transforming our categorical prediction to a regression one.
Q: What is Model Pruning? A: Model pruning is the art of discarding those weights that do not signify a model’s performance. https://towardsdatascience.com/scooping-into-model-pruning-in-deep-learning-da92217b84ac
RandomForestRegressor in Scikit-Learn can be used https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestRegressor.html
Using Random Forest for Rating Prediction
https://www.researchgate.net/publication/309775673_A_random_forest_approach_for_rating-based_recommender_system ”… movies and the values are centered on zero by subtracting the mean from the respective elements.”
- should we center our values around zero too by substracting the mean?
- centered age with its average